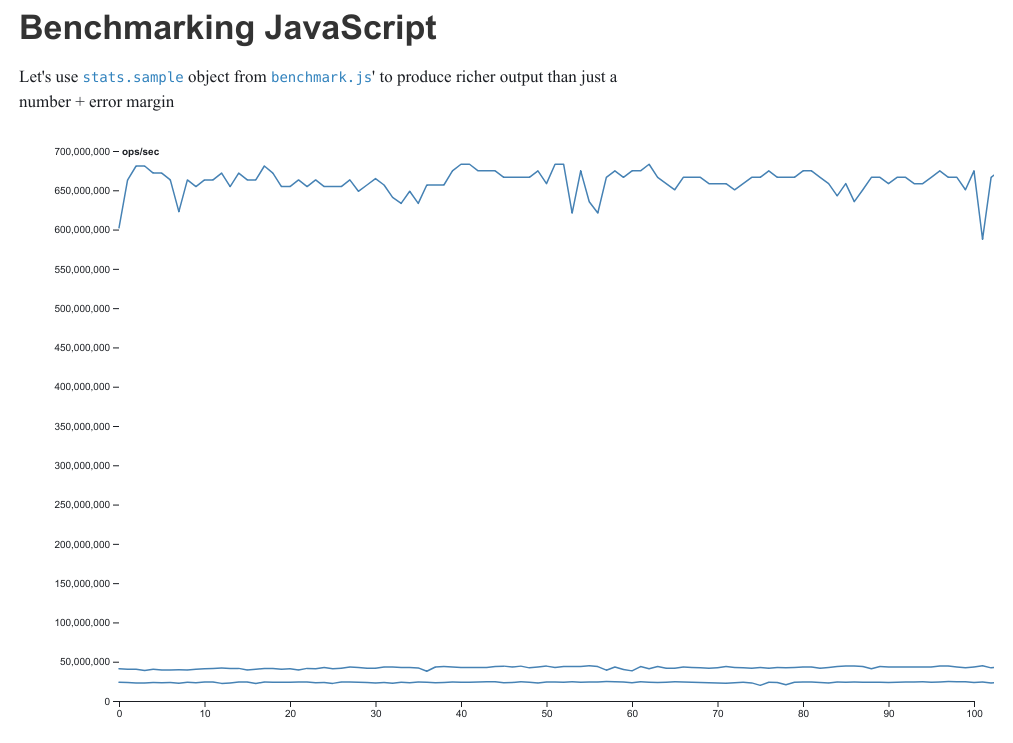
TL;DR: Could Observable be used to make notebook that gives us richer benchmarking information?
Benchmarking sites for JavaScript typically present the results like this:




As I’m sure people coming to a data-viz oriented forum will know, this is a needlessly reductive and unhelpful way of presenting the data that will give very misleading results. A distribution or a line plot showing iteration vs performance would give us a much better idea of the actual characteristics. We could even cram the two into one by using a stacked bar chart to show the distribution of ops/second, while making the gradient depend on which iteration the data point was from, or a horizon chart or ridgeline plot which plots each run (as in a batch of iterations) separately.
So I’m thinking: wouldn’t it be nice if we had some kind of Benchmarking Template notebook that let you benchmark snippets of JavaScript code, and then produces richer data visualizations that actually give you much more workable information?
Also, given that we would be running a full notebook environment it would then be exceedingly easy to modify and get more detailed information compared to traditional benchmarking sites.
Sadly, there is a lot more to benchmarking that just a nested for-loop + timing before and after. I’m not even talking about the statistics of it: we have to consider whether or not the JS engine can optimize the function or not (for example, eval never is, and using closures complicates the picture too), whether we perform DOM operations during the measurements that may interfere with it, and so on.
I don’t know the best practices to ensure that code snippets are run like JS would normally run on a webpage. I think that’s part of why jsperf still is seen as more reliable though, since it uses PHP to statically generate a site with all the code. Who knows, perhaps the way Observable works is inherently getting in the way of that.
Does anyone here have any ideas where to start with that?
Anyway, for the interested, here is some further viewing/reading on this topic:
Kay Ousterhout - Software Performance: A Shape, Not A Number (StrangLoop 2018 talk on YouTube) - this was about performance measurement of live systems rather than benchmarking, but most of the ideas translate directly
StackOverflow: Which JS benchmark site is correct? - touches on the fact that many benchmarking sites come with their own overhead and interference that makes the resulting values suspicious
Why Is Looping Through An Array So Much Faster Than JavaScript’s Native IndexOf? - A rant an answer I gave on StackOverflow about misleading benchmarking practices.
Zed Shaw - Programmers Need To Learn Statistics Or I Will Kill Them All - great insights (if you can get past the anger) into common mistakes in benchmarking